Academic
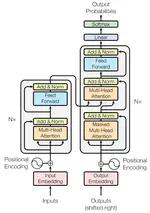
Flash Attention 是目前针对 Attention 计算最优解决方案的开山工作,旨在从底层 GPU 的 HBM(High Bandwidth Memory)和 GPU 的片内 SRAM(Static Random Access Memory)的角度尽可能降低访存开销,从而加速 Attention 的计算,在长序列的情况下展现出了优良的性能。
然而,Flash Attention 对于 LLM 初学者来说很不好理解,因为它需要我们对 Attention 的计算过程有非常深入的了解,而其中的难点在于 Softmax 的计算的可分割性的理解。本文希望通过丰富的插图乃至动画,让 Flash Attention 能够通俗易懂。
随着 AI 的飞速发展,特别是伴随着 ChatGPT 的诞生,标志着深度学习已经进入了大语言模型(Large Language Models,LLM)的时代。然而,LLM 由于其本身的复杂性和大规模而给部署和服务带来了前所未有的挑战。
来自卡内基梅隆大学的 Catalyst 团队在他们的最新综述论文中,从机器学习系统的研究视角出发,详细分析了前沿 LLM 推理从算法到系统的产生的重大变革。