An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
【文献精读】Vision Transformer (ViT)
Vision Transformer (ViT) 是目前计算机视觉 (CV) 领域影响力最大的一项工作,因为他挑战了自从 2012 年 AlexNet 提出以来的 CNN 模型在 CV 领域的绝对统治地位。实验表明,如果能够在足够多的数据集上做预训练,那么即使不使用 CNN 也能达到同等甚至更高的精度。
ViT 不仅在 CV 领域挖了一个大坑,而且还打破了 CV 和 NLP 在模型上的壁垒,所以在多模态领域也挖了一个大坑。于是,在 2020 年 10 月本文在 arXiv 上公开以后,基于 ViT 的工作层出不穷。毫无疑问,ViT 标志着 Transformer 模型正式杀入 CV 界,也标志着 Transformer 模型正式成为继 MLP、CNN、RNN 之后的一种新的模型范式。
特别鸣谢
本文结合亚马逊首席科学家李沐的深度学习论文精读系列视频进行整理。视频的主讲人是朱毅研究员。
Abstract
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to replace certain components of convolutional networks while keeping their overall structure in place. We show that this reliance on CNNs is not necessary and a pure transformer applied directly to sequences of image patches can perform very well on image classification tasks. When pre-trained on large amounts of data and transferred to multiple mid-sized or small image recognition benchmarks (ImageNet, CIFAR-100, VTAB, etc.), Vision Transformer (ViT) attains excellent results compared to state-of-the-art convolutional networks while requiring substantially fewer computational resources to train.
作者认为,Transformer 在 NLP 领域应用广泛并且成为标准,但在 CV 领域的应用仍然有限。注意力 attention 机制要么与 CNN 结合使用,要么用于替换 CNN 中的某些部分而整体结构不变。作者通过实验证明,这种对 CNN 的依赖是不必要的,直接将序列化的图像块 patches 输入进 Transformer 可以取得非常好的效果。尤其是在大规模的数据集上做预训练之后,再迁移到中小型数据上能够获得和最好的 CNN 相媲美的结果。
朱老师提醒大家特别注意,这里作者说的花费更少的资源训练是指 TPU v3 训练 2500 天所花费的资源!
Introduction
Self-attention-based architectures, in particular Transformers (Vaswani et al., 2017), have become the model of choice in natural language processing (NLP). The dominant approach is to pre-train on a large text corpus and then fine-tune on a smaller task-specific dataset (Devlin et al., 2019). Thanks to Transformers’ computational efficiency and scalability, it has become possible to train models of unprecedented size, with over 100B parameters (Brown et al., 2020; Lepikhin et al., 2020). With the models and datasets growing, there is still no sign of saturating performance.
在 NLP 领域,目前主流的方式是先在一个大规模数据集上做预训练 pre-train,然后在特定领域的小数据集上做微调 fine-tune。(这实际上是 BERT 这篇论文里提出来的。)Transformer 的计算具有高效性 efficiency 和可扩展性 scalability,并且随着模型和数据集的增长,还没有看到出现性能饱和 saturating 的现象。
Transformer 直接用于 CV 领域的困难
朱老师认为,在过去的工作中,Transformer 一直没能用于 CV 领域的原因是因为计算的复杂性。
我们试想,如果我们偏要把图片当成序列送入 Transformer 里面训练该怎么做?我们很容易想到的是将二维的图片拉直成序列,然后就可以输入到 Transformer 里面了。然而这样的计算复杂度就达到 $O(n^2)$。如果输入图片为 224x224x3,即使不考虑通道,序列长度就高达 50176,这远远大于一句话甚至是一段话的长度。
In computer vision, however, convolutional architectures remain dominant (LeCun et al., 1989; Krizhevsky et al., 2012; He et al., 2016). Inspired by NLP successes, multiple works try combining CNN-like architectures with self-attention (Wang et al., 2018; Carion et al., 2020), some replacing the convolutions entirely (Ramachandran et al., 2019; Wang et al., 2020a). The latter models, while theoretically efficient, have not yet been scaled effectively on modern hardware accelerators due to the use of specialized attention patterns. Therefore, in large-scale image recognition, classic ResNet-like architectures are still state of the art (Mahajan et al., 2018; Xie et al., 2020; Kolesnikov et al., 2020).
目前 CNN 在 CV 仍占主导地位。既然 Transformer 在 NLP 领域又特别火,注意力机制又那么香,为什么不可以在 CV 领域使用 Transformer 呢?其实是有相关工作的,一些工作将 CNN 和 self-attention 结合使用。例如,可以将网络中间的特征图当作是 Transformer 的输入。Ramachandran 等人认为可以添加一个小窗口以降低 Transformer 的计算复杂度,Wang 等人认为可以分别在图片的两个维度(宽和高)做自注意力。
作者认为,上述优化理论上都是可行的,但是都是比较特殊的自注意力操作,很难在硬件上加速,训练更大的模型。个人认为,这种优化缺乏普适性。因此,传统的残差网络依然是最好的。
Inspired by the Transformer scaling successes in NLP, we experiment with applying a standard Transformer directly to images, with the fewest possible modifications. To do so, we split an image into patches and provide the sequence of linear embeddings of these patches as an input to a Transformer. Image patches are treated the same way as tokens (words) in an NLP application. We train the model on image classification in supervised fashion.
作者是被 Transformer 在 NLP 领域应用的可扩展性所启发,所以他们希望将 Transformer 直接作用于图片而尽量做少的修改。作者将图片打成了很多个 patch,每一个 patch 的大小是 16x16。然后我们就可以将每一个 patch 当成是 NLP 领域里的单词,这也就是本文标题 An Image is Worth 16x16 Words 的含义。这里作者还补充说明了训练方式是有监督训练,因为 NLP 领域绝大多数都是无监督训练。
朱老师认为,读到这里可以认为作者真的是完全把 CV 任务当成是 NLP 任务去做。朱老师觉得本文其实是换了个角度讲故事,但是总而言之本文的作者只想说明一件事——Transformer在视觉领域也能取得很好的效果。
When trained on mid-sized datasets such as ImageNet without strong regularization, these models yield modest accuracies of a few percentage points below ResNets of comparable size. This seemingly discouraging outcome may be expected: Transformers lack some of the inductive biases inherent to CNNs, such as translation equivariance and locality, and therefore do not generalize well when trained on insufficient amounts of data.
如果在中等大小的数据集(ImageNet)上不加以强约束,ViT 其实是比传统的残差网络更弱的。作者于是就解释到,看起来不太好的结果其实是可以预知的。因为 Transformer 和 CNN 相比它缺少 CNN 有的归纳偏置 inductive biases,它指的是一种先验知识,或者是我们提前做好的假设。
CNN 其实是有两个归纳偏置。一个是 locality,因为卷积运算是一个滑动窗口一点一点在图片上做的,所以就可以假设图片中相邻的区域有相似的特征。另一个是平移同变性 translation equivariance,用公式表示就是 $f(g(x)) = g(f(x))$。(这里将 $f$ 理解为卷积,$g$ 理解为平移。)
正因为 CNN 有这两个归纳偏置,所以 CNN 在卷积之后只需要相对更少的数据就能够学到更多的特征,得到一个更好的模型。但是对于 Transformer 来说,它其实没有这些先验信息,所以 Transformer 里的所有参数都需要从数据里面自己学习。
However, the picture changes if the models are trained on larger datasets (14M-300M images). We find that large scale training trumps inductive bias. Our Vision Transformer (ViT) attains excellent results when pre-trained at sufficient scale and transferred to tasks with fewer datapoints.
果然,上了大数据以后没有归纳偏置的 Transformer 的效果要优于 CNN。
Conclusion
按照沐神读论文的方式,先来看看结论。
We have explored the direct application of Transformers to image recognition. Unlike prior works using self-attention in computer vision, we do not introduce image-specific inductive biases into the architecture apart from the initial patch extraction step. Instead, we interpret an image as a sequence of patches and process it by a standard Transformer encoder as used in NLP. This simple, yet scalable, strategy works surprisingly well when coupled with pre-training on large datasets. Thus, Vision Transformer matches or exceeds the state of the art on many image classification datasets, whilst being relatively cheap to pre-train.
本文工作最大的特点是几乎不需要任何对 CV 领域有特别深的了解,只需要把图片当成是 NLP 领域当中的序列,即序列化的图像块,就可以用 Transformer 来做了。这种方法简单、可扩展性高,并且和大规模预训练结合起来的时候效果出奇地好。
While these initial results are encouraging, many challenges remain. One is to apply ViT to other computer vision tasks, such as detection and segmentation. Our results, coupled with those in Carion et al. (2020), indicate the promise of this approach. Another challenge is to continue exploring self-supervised pre-training methods. Our initial experiments show improvement from self-supervised pre-training, but there is still large gap between self-supervised and large-scale supervised pre-training. Finally, further scaling of ViT would likely lead to improved performance.
ViT 属于挖坑型论文,这篇论文其实是挖了一个新模型的坑,即如何将 Transformer 应用到 CV。因此,很自然可以想到的第一个问题是,ViT 能否在除了图像分类任务以外的任务上也达到很好的效果?例如语义分割 segmentation 和目标检测 detection。事实也的确如此,短短两个月不到,目标检测领域就出来了一个新的工作 ViT-FRCNN1,这就已经把 ViT 用到目标检测上了。同年 12 月,语义分割也有一篇 SETR2。
朱老师在这里不得不吐槽一波,大家的手速实在是太快了,CV 圈卷的程度已经不能用月来计算了!而且紧接着三个月后,Swin Transformer3 横空出世,把多尺度设计融合到 Transformer 里面,真正让 Transformer 更适合来做 CV。
另外一个可以探索的方向是自监督的训练方式,因为在 NLP 领域几乎所有基于 Transformer 的模型全都采用自监督的方式训练。本文也做了一些自监督训练的实验,但发现和有监督的训练比起来效果有明显差距。
毕竟作者是 Google Brain,反正也没有谁有足够的计算资源能够填本文挖的大坑,那就自己来填吧!结果半年以后作者又提出了 Scaling Vision Transformer (ViT-G)4,其实就是更大的 ViT,然后就把 ImageNet 数据集的准确率刷到 $90\%$ 以上了。
这篇论文不光是挖了一个 CV 大坑,更是待到 CV 和 NLP 大一统之后,挖了一个多模态的大坑。多模态深度学习领域的工作最近也呈井喷式增长,由此可见 ViT 这篇论文的影响力是多么巨大。
Related Work
Transformers were proposed by Vaswani et al. (2017) for machine translation, and have since become the state of the art method in many NLP tasks. Large Transformer-based models are often pre-trained on large corpora and then fine-tuned for the task at hand: BERT (Devlin et al., 2019) uses a denoising self-supervised pre-training task, while the GPT line of workuses language modeling as its pre-training task (Radford et al., 2018; 2019; Brown et al., 2020).
Transformer 模型目前一般都是先在一个大规模语料库上做预训练,然后在目标任务上做一些细小的微调。这里面有两大著名的工作:BERT5 和 GPT6。BERT 用的是一个被称为 denoising 的自监督方式,其实就是完形填空。而 GPT 则使用 language modeling 做自监督,它是指已经有一个句子,预测下一个词是什么。
Naive application of self-attention to images would require that each pixel attends to every other pixel. With quadratic cost in the number of pixels, this does not scale to realistic input sizes. Thus, to apply Transformers in the context of image processing, several approximations have been tried in the past.
Many of these specialized attention architectures demonstrate promising results on computer vision tasks, but require complex engineering to be implemented efficiently on hardware accelerators.
将自注意力简单地应用到图像的每个像素上会导致很大的计算开销,所以自注意力很难直接用到 CV。因此,想要用自注意力来处理图像就必须做一些近似 approximation。下面作者列举了很多自注意力在 CV 领域的应用。例如只对邻近的像素做自注意力,或者只对一些稀疏的点做自注意力。但这些工作从本质上讲都是减少处理的数据大小,以求近似。许多这些专门的注意力架构在计算机视觉任务上展示了有希望的结果,但需要复杂的工程才能在硬件加速器上有效实施。
本文这么简单的 idea 难道就没有人想到吗?其实是有类似的,作者在相关工作里面这样描述:
Most related to ours is the model of Cordonnier et al. (2020), which extracts patches of size 2 ×2 from the input image and applies full self-attention on top. This model is very similar to ViT, but our work goes further to demonstrate that large scale pre-training makes vanilla transformers competitive with (or even better than) state-of-the-art CNNs. Moreover, Cordonnier et al. (2020) use a small patch size of 2×2 pixels, which makes the model applicable only to small-resolution images, while we handle medium-resolution images as well.
ICLR 2020 有一个工作是在 CIFAR-10 数据集上切 2x2 的 patch,然后在上面做 self-attention。作者认为他们的工作和这项工作的区别是在大规模数据集上做预训练,不需要任何改动就能取得比目前最好的 CNN 还好的效果。
There has also been a lot of interest in combining convolutional neural networks (CNNs) with forms of self-attention, e.g. by augmenting feature maps for image classification (Bello et al., 2019) or by further processing the output of a CNN using self-attention, e.g. for object detection (Hu et al., 2018; Carion et al., 2020), video processing (Wang et al., 2018; Sun et al., 2019), image classification (Wu et al., 2020), unsupervised objectdiscovery (Locatello et al., 2020), or unified text-vision tasks (Chen et al., 2020c; Lu et al., 2019; Li et al., 2019).
还有很多将 CNN 和自注意力结合起来的工作,而且基本涵盖了 CV 领域的很多任务。
Another recent related model is image GPT (iGPT) (Chen et al., 2020a), which applies Transformers to image pixels after reducing image resolution and color space. The model is trained in an unsupervised fashion as a generative model, and the resulting representation can then be fine-tuned or probed linearly for classification performance, achieving a maximal accuracy of 72% on ImageNet.
一个特别新的工作是 image GPT (iGPT)。我们知道 GPT 是 NLP 领域的代表工作,iGPT 类似,它是一个生成式模型,用无监督的方式取训练的。但是这项工作的准确率最高仅仅只有 $72\%$,而本文的准确率已经达到 $88.5\%$ 了。但是另一个之后的工作 MAE7 却反而让生成式模型比之前的判别式模型效果更好,随后爆火。
Our work adds to the increasing collection of papers that explore image recognition at larger scales than the standard ImageNet dataset.
最后作者提到了比 ImageNet 还大的数据集上各个模型的效果。
总结一下,本文的相关工作列举得非常彻底,基本上和本文工作相近的工作都涵盖到了。朱老师认为,在写相关工作章节时,就是要让读者知道在你的工作之前,别人做了哪些工作,你和他们的区别在哪里。这个只要写清楚了,其实是对你非常有利的,并不会因此降低论文的创新性,反而会让这个文章变得更加简单易懂。
Method
In model design we follow the original Transformer (Vaswani et al., 2017) as closely as possible. An advantage of this intentionally simple setup is that scalable NLP Transformer architectures – and their efficient implementations – can be used almost out of the box.
作者强调,ViT 在模型设计上是尽可能按照最原始的 Transformer 来做的。这样做的最大好处就是可以直接把 NLP 领域成功的 Transformer 架构直接拿过来使用,不需要再魔改模型了。
Vision Transformer (ViT)
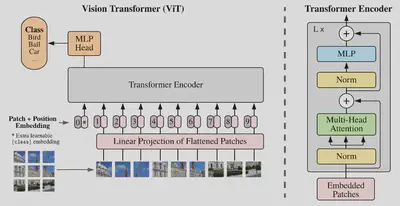
朱老师认为,论文的总览图非常重要。总览图画得好,别人在不读整篇文章的情况下光看图就能够大致了解这篇文章在讲什么。ViT 这篇文章的总览图画得非常好,以至于其他人在引用或者讲解 ViT 的时候都是直接把图贴上去而不做任何修改。
给定一张图片,首先将这张图打成了很多 patch。然后他把这些 patch 转化成一个序列,每个 patch 会通过一个被称为线性投射层的操作得到一个特征,即图中的 Patch + Position Embedding。我们知道,自注意力机制是所有的元素之间两两去做交互,所以说 attention 本身不存在顺序问题。但是对于图片来说它是一个整体,这个九宫格是有自己的顺序的。如果顺序颠倒了,就不是原来那张图片了,所以就需要 Position Embedding。加上了位置编码的信息以后,每个 token 既包括了原本的图像 patch 信息,又包括了图像 patch 所在的位置信息。
接下来实际上就和 NLP 那边是完全一样了。经过 Transformer Encoder 之后,它会给我们很多输出。那么问题来了,应该用哪个输出去做最后的分类呢?这里还需要再次借鉴 BERT5 当中的 extra learnable [class] embedding,即特殊字符 cls。在 ViT 中也加入了一个特殊字符,用 * 代替,它的位置信息永远是 0。因为自注意力机制使得每个 token 之间都在互相学习,用一个空的 token 就可以和图片的每个 patch 交互学到完整的图片信息,所以只需要根据 cls 对应的输出来判断即可。MLP Head 就是一个通用的分类头了,最后再用交叉熵函数去进行模型的训练。
至于这里的 Transformer Encoder 也是完全标准的,即图中右边的部分。所以说从整体结构上来看,ViT 的结构非常简洁,它的特殊之处就在于如何将一个图片转化成一系列的 token。
那么下面结合下图 ViT 的 Transformer 部分对 Transformer 模型再做一个回顾。

首先将输入的图片打成若干 patch,这里的图片输入大小为 224x224x3,表示宽和高为 224 像素,RGB 3 通道。patch 的大小为 16x16x3,因此原图被划分为 $14 \times 14 = 196$ 个 patch。再加上 cls,序列的总长度为 197。
经过 Embedding 和位置编码之后,得到维度为 197x768 的 tokens,因为每个 16x16x3 的 patch 拉直之后是 $16 \times 16 \times 3 = 768$ 维。
接下来进行 Self-Attention,需要映射出 3 个矩阵 Query、Key 和 Value。由于 Transformer 的多头自注意力机制,并且 ViT 设置了 $h = 12$ 个头,那么 3 个矩阵的维度均为 197x64,因为 $768 \div 12 = 64$。最后经过拼接 Concat 得到 197x768 维的 Attention 矩阵。
最后经过 MLP 全连接层,一般先把维度放大 4 倍,即 197x3012,再回到原来的维度上输出。这就是 Transformer 一层 Encoder 上的计算过程。
Inductive bias
We note that Vision Transformer has much less image-specific inductive bias than CNNs. In CNNs, locality, two-dimensional neighborhood structure, and translation equivariance are baked into each layer throughout the whole model. In ViT, only MLP layers are local and translationally equivariant, while the self-attention layers are global. The two-dimensional neighborhood structure is used very sparingly: in the beginning of the model by cutting the image into patches and at fine-tuning time for adjusting the position embeddings for images of different resolution (as described below). Other than that, the position embeddings at initialization time carry no information about the 2D positions of the patches and all spatial relations between the patches have to be learned from scratch.
作者还补充了归纳偏置的一些细节。ViT 相较于 CNN 而言要少很多这种图像特有的归纳偏置,例如 CNN 当中有平移性和模型的局部等变性(详见前文)。但是对于 ViT 来说,MLP 是有上述的这些归纳偏置的,但是自注意力层是全局的 global,即图片的 2D 信息自注意力层没怎么用。(基本上仅仅只是 Position Embedding 的时候用到了。)另外,位置编码也是随机初始化的,并没有携带任何 2D 信息,所有的 patch 之间的距离信息、场景信息都得重头学。
作者补充这一段的目的是为了给后面在中小数据集上 ViT 不如 CNN 的实验结果的解释做铺垫。那么既然如此,Transformer 在全局上表现如此优秀,CNN 又在中小数据集上快速收敛,是不是可以将它们结合起来?
Hybrid Architecture
As an alternative to raw image patches, the input sequence can be formed from feature maps of a CNN (LeCun et al., 1989). In this hybrid model, the patch embedding projection E (Eq. 1) is applied to patches extracted from a CNN feature map. As a special case, the patches can have spatial size 1x1, which means that the input sequence is obtained by simply flattening the spatial dimensions of the feature map and projecting to the Transformer dimension. The classification input embedding and position embeddings are added as described above.
其实将 Transformer 和 CNN 的想法是可行的。我们假设现在不把图片打成 patch 了,而是用一个 16x16 的卷积核去对原始图片进行卷积(步长也为 16),得到的也是一个 14x14 的特征图。后续的操作和 ViT 一样,将特征图的每个像素当成 NLP 任务送入 Transformer Encoder 中。
Fine-tuning and Higher Resolution
When feeding images of higher resolution, we keep the patch size the same, which results in a larger effective sequence length. The Vision Transformer can handle arbitrary sequence lengths (up to memory constraints), however, the pre-trained position embeddings may no longer be meaningful. We therefore perform 2D interpolation of the pre-trained position embeddings, according to their location in the original image. Note that this resolution adjustment and patch extraction are the only points at which an inductive bias about the 2D structure of the images is manually injected into the Vision Transformer.
微调 fine-tuning 是指预训练好的 ViT 模型(输入图片为 224x224x3)在更大尺寸的图片(例如 320x320x3)上进行“刷脸”。但是,这对于预训练好的 ViT 有些麻烦,因为如果 patch 的大小不变,而图片变大了,于是序列变长了。从理论上说,Transformer 可以处理任意长度的序列。但是,提前训练好的位置编码可能就完全没用了,因为预训练好的位置编码具有明确的物理意义。那么预训练的位置编码还是否有用呢?作者发现,再做一个 2D 的差值就可以了。但这里的差值也仅仅只是一个临时的解决方案,应该说这算是 ViT 在微调的时候的一个局限性。
Experiments
-
Beal J, Kim E, Tzeng E, et al. Toward transformer-based object detection[J]. arXiv preprint arXiv:2012.09958, 2020. ↩︎
-
Zheng S, Lu J, Zhao H, et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 6881-6890. ↩︎
-
Liu Z, Lin Y, Cao Y, et al. Swin transformer: Hierarchical vision transformer using shifted windows[J]. arXiv preprint arXiv:2103.14030, 2021. ↩︎
-
Zhai X, Kolesnikov A, Houlsby N, et al. Scaling vision transformers[J]. arXiv preprint arXiv:2106.04560, 2021. ↩︎
-
Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018. ↩︎ ↩︎
-
Radford A, Narasimhan K, Salimans T, et al. Improving language understanding by generative pre-training[J]. 2018. ↩︎
-
He K, Chen X, Xie S, et al. Masked autoencoders are scalable vision learners[J]. arXiv preprint arXiv:2111.06377, 2021. ↩︎
Bowen Zhou
Student pursuing a PhD degree of Computer Science and Technology
My research interests include Edge Computing and Edge Intelligence.